

Lubrizol Corp. v. IBM Order on Slack and Teams
Lubrizol Corp. v. IBM Order on Slack and Teams
Court requires producing parties to provide context around responsive messages. How could we do that for Teams?

Welcome to the preview edition of Mike McBride on M365, which might just get abbreviated to MM on M365 very soon because I dread the embarrassment of spelling my own name incorrectly, and that is bound to happen if I have to type it enough. This newsletter is something I’ve had in the back of my mind for over a year now, but couldn’t do it while I was working for a company that provided consulting services around M365 Purview. Now that I’ve been yet another victim of layoffs, I think it’s time to provide a deep dive into M365 from the perspective of someone who’s been in the eDiscovery industry for over 15 years. Please consider subscribing if this kind of insight is valuable to you. Paid subscribers will get this kind of writeup every two weeks, while free subscribers will still get some issues and links to important M365 information.
What better item to start with than a recent court decision about Slack and Teams messages?
For the legal background of this decision, I will point you to the extremely capable hands of Kelly Twigger, who had this as the Case of the Week.
Her description focuses on Slack, which is appropriate as the dispute really was about Slack. This isn’t MM on Slack though, so the really interesting part of the decision was this:
For the foregoing reasons, Lubrizol's motion to compel is GRANTED. Within 28 days of this Memorandum Opinion and Order, IBM is hereby ordered to produce: (1) the entirety of any Slack conversation containing 20 or fewer total messages that has at least one responsive message; and (2) the 10 messages preceding or following any responsive Slack message in a Slack channel containing more than 20 total messages. Within 28 days, Lubrizol shall do the same with respect to its Microsoft Teams messages.
That got my attention. Knowing what we know about how Teams messages are stored, and collected, how would we comply with this order?
First Question - Where Were the Responsive Messages?
If I’m the eDiscovery person challenged with this order, the first thing I need to know is where the messages are coming from. Are they from private or group chats? Are they in Teams channels? If so, are the channels Public, Private, or Shared channels?
Because it matters when it comes time to collect and identify the surrounding messages.
Chats - messages are stored in the mailbox of each person involved in the chat.
Public Channels - messages are stored in the group mailbox for that Team.
Private channels - messages are stored in the mailbox of each member of the private channel.
Shared channels - messages are stored in the group mailbox, but there may be some extra steps involved in collecting them.
So, my strategy is going to depend on which type of message was responsive.
Of course, that is only the beginning of our journey.
Next Stop - Threads and Conversations
Before acting on the next step, I’m probably going to have to confer with my legal team. I’m not a lawyer so it’s not my role to interpret the order, but I would want to clarify how we handle the 10 messages preceding and following a message in a channel when those messages may cross over multiple threads. For the sake of continuing this exposition, I’m going to assume we’ve gone back and clarified that we are looking for the individual thread and not every thread in a channel, but in real life, I’m going to ask for clarity. Here’s an example, which thread would you produce if your responsive message was the one with “20230523” in it?
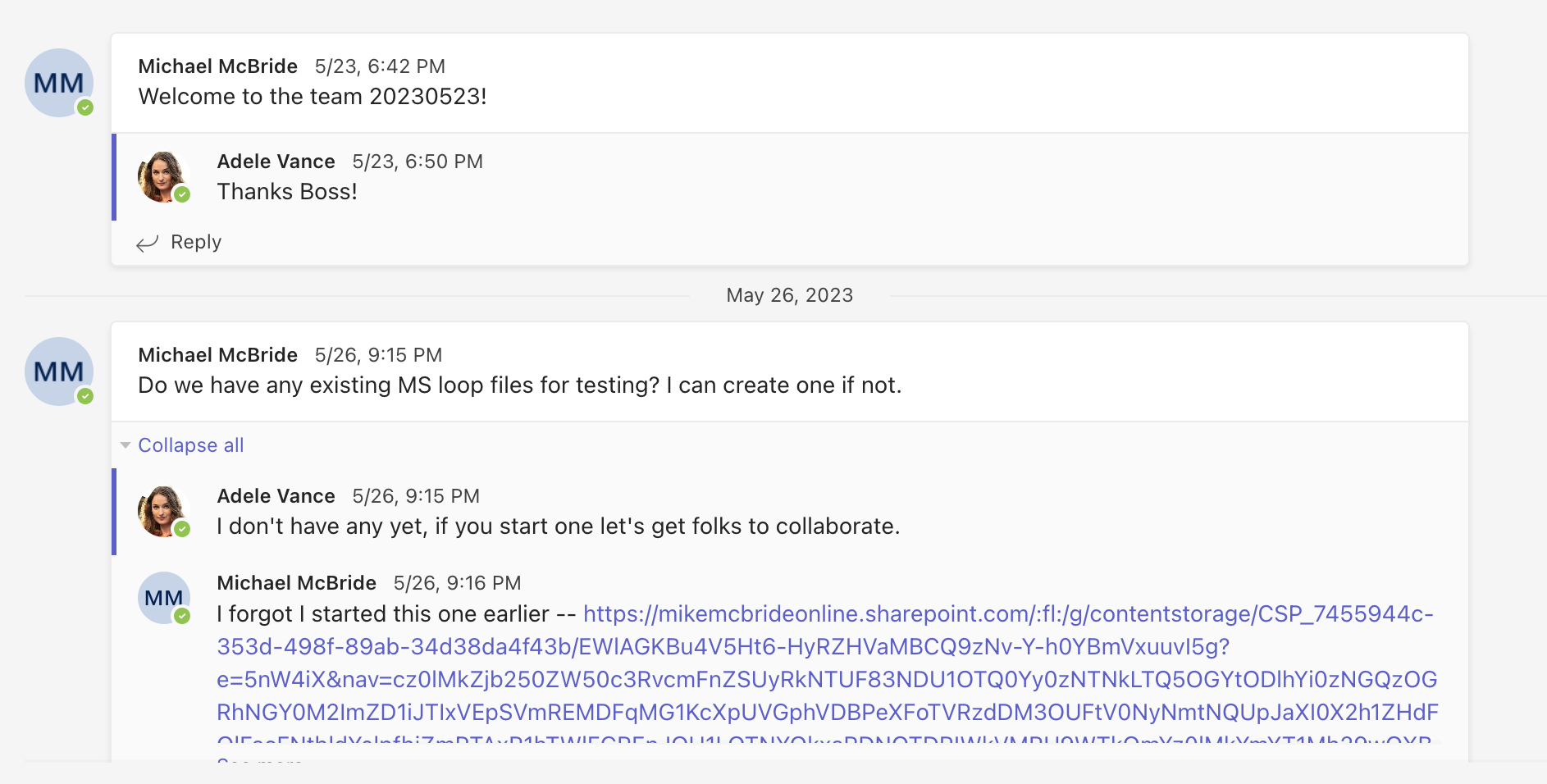
So, with chats and channel messages now, we know that we are looking for individual threads. This becomes my first barrier.
Using the Purview eDiscovery Tools there’s no “easy” button that says to collect these messages plus the 10 messages preceding and following it in the same thread. In fact, the thread IDs and Channel names aren’t fields that we can run a search against. That’s going to require us to over-collect and locate those messages downstream.
The Process Using Purview Standard (E3 licensing)
Once we’ve identified the locations where responsive messages live, collecting them in Standard eDiscovery is fairly straightforward. That’s not to say it’s easy. There’s going to be some manual labor involved.
You’ll be collecting from the mailboxes that had responsive messages.
My hope is that there’s at least a date range filter in place for the agreed-upon searches, otherwise, we’ll have to collect the entire mailbox, or at least all of the Teams messages from the mailbox.
You can base a search on Message Kind or ItemClass to limit it to just Teams messages.
At this point, we’ll be taking those messages out of the M365 environment as a PST and loading that into our processing tool.
This is where we pause to mention that you’ll need to make sure your processing tool and the workflow you use to bring that data to your review platform, is going to include the metadata that tells us where the messages came from. You’ll want those Thread IDs, Channel Name, and Message Type fields here.
Once in the review platform, you’ll use the search functions to identify the documents responsive to the original search terms and any messages from the same thread. This process will vary depending on the review platform and the available tools you have, but this generic workflow should work.
Then we’ll just start counting. For threads with less than 20 messages, we’ll produce all of the messages, and for threads that are longer, we’ll produce the 10 messages preceding and following the responsive ones.
The Process using Premium eDiscovery (E5 licensing)
In Purview eDiscovery Premium, Microsoft will do a lot of this work for you, but it will do it in a specific way that may not line up with this order very well. Since Premium eDiscovery allows us to collect and review our data prior to exporting it out of the M365 platform, it can tie together threads and present us with the context we are required to produce in this case.
Again, similar to what we were doing with Standard, we’ll be collecting the Teams messages from the responsive mailboxes.
In eDiscovery Premium, however, our default option will be to collect “Contextual” Teams messages and cloud attachments.
This means we can run the search terms the same way we did before, to identify the responsive messages.
The Premium eDiscovery tool will automatically collect the messages surrounding the responsive message and add them to the HTML transcript of the conversation. For channels, the transcript will contain the entire thread. For chat, it will collect messages in the same thread in a 24-hour period. (Roughly 12 hours on either side of the responsive message.)
Premium will also collect any documents that it can from any links it finds in the messages and add them as children to the Teams message transcript.
We can export those transcripts and family documents to a load file that can be imported into our review platform and produced from there.
There are, however, some caveats that are important to mention here.
You will get the “contextual” messages as defined by the Premium eDiscovery processing, which may or may not meet the written requirements.
The context of any chat message will be the 24-hour period it falls in, not a specific number of messages surrounding it.
Channel threads will be collected in their entirety regardless of how many messages were in the original thread.
The exported data from M365 will not contain individual messages with metadata for each message. It will be the transcript generated during collection and processing. The metadata will generally reflect the first message in the transcript. This can make your date references appear inaccurate.
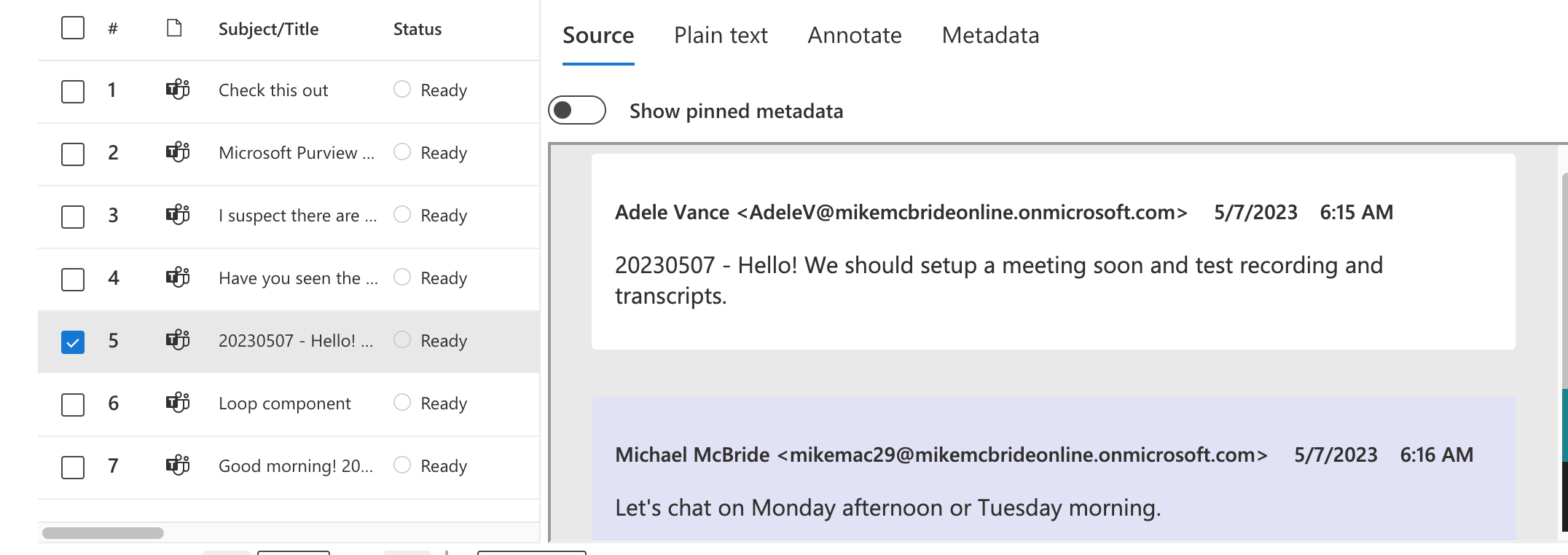
Example of multiple messages collected as a transcript.
The collection of the linked attachment is subject to some additional policies that may or may not be in place. (This will be a whole future issue in and of itself.) If no other action was taken, however, the eDiscovery tool will simply follow the link and collect the document that is currently at that link. This may not be representative of what was shared at the time of the message. Documents get changed over time.
Final Thoughts:
Putting myself in the shoes of an eDiscovery practitioner, there are a few things I would want my legal team to clarify with the Court.
1. As I mentioned above, let’s clarify that a channel might have multiple threads, and we are only required to produce the messages in the same thread as the responsive one.
2. I’m going to want to lay out these two scenarios and determine if the second one is “close enough” to the requirements. In my layman’s opinion, I think the transcripts from Premium eDiscovery provide the context that was being requested here even if they aren’t going to provide the exact number of messages requested. Plus, it will provide any linked attachments, which is kind of a bonus. It’s also possible that some third-party tool could provide some alternatives here, but that’s outside of my ability to test everything!
3. Prior to going to Court, I’m going to take a good look at what any agreed-upon ESI protocol says. This is where I see a lot of legal teams getting bit by the way Premium eDiscovery handles those messages and transcripts. Their protocol requires them to produce the metadata for individual messages. This gets difficult when Microsoft doesn’t include it to be produced.
What would you do if you were faced with this kind of order? What creative ways have you seen teams collect Teams messages and provide context around the direct search hits?
Let us know in the comments, and let us know if you have any burning questions about M365 Purview and eDiscovery. It might become a newsletter topic in the near future.